Infrastructure upgrades and patch management downtime
Purpose of this document
Goal:
- Consider different approaches to patch management.
- Outline possible deployment strategies for Atlassian products.
Not a goal:
- Provide official stances or guidance on behalf of Atlassian
- (This is a technical, professional IT Engineer opinion, but this is not vetted by Support)
Background on patch management
Definition(s):
The systematic notification, identification, deployment, installation, and verification of operating system and app software code revisions. These revisions are known as patches, hotfixes, and service packs.
The approach for patch management and state-of-the-art deployment for Atlassian Data Center apps is no different than for other apps run by IT teams all over the world across industries. However, teams using Atlassian tools often feel the effects of patching or deployment decisions more strongly, due to the highly collaborative and mission-critical nature of the tools.
Our business requirements drive our strategy to achieve patching compliance. These business requirements can differ across enterprises.
This document strives to compare two very different approaches using general examples.
Acme Co
Manages VMs by logging into VMWare Console and manually provisioning the OS via NetBoot
Has Snowflake VMs that do not adhere to common software or automated monitoring
Installs each Atlassian app by hand by unpacking the .tar file or .zip file and manually modifying configuration files; does not check configuration files into a Version Control System such as git
Performs patches manually
Syntho Corp
Uses Terraform, Atlassian Bitbucket, and Bamboo to dynamically provision VMs based on checked-in properties files in a format such as .yaml Has VMs that are automatically created via a set of rules using the checked-in properties files. These include standard packages, lifecycle information, and automated monitoring
Performs patching automatically by regularly creating new nodes and destroying old nodes on a schedule
Let’s dive into these differences below.
Different approaches to patch management
The following is out of scope for Atlassian Support or the Advisory Services program:
Patching for the database
Patching for server operating systems
Patching for other pieces of IT Infrastructure related to supporting Atlassian Data Center apps
Instead, we’ll speak more generally about the theory of applying this information to Atlassian Data Center apps.
The examples below compare a very typical and more modern approach to using cloud technologies to deploy apps and services. This is biased and makes assumptions, but these examples are simply an exercise in rethinking approaches.
In this scenario, we hypothesize having to fit within a specific compliance regulation while also needing to meet business uptime requirements. Balancing these requirements may require new solutions and drive needed funding.
Security requirements
Severity | Days to patch |
|---|
Low/Medium | 90-day sliding window |
High | 30-day sliding window |
Business SLA
Service | Tier | SLA |
|---|
Daily task | Tier 3 | 99% uptime during business hours (8 a.m. until 6 p.m.) and no guarantee outside those core hours |
Core tool | Tier 2 | 99.95% uptime during business hours (8 a.m. until 6 p.m.) and less availability outside those core hours |
Business critical | Tier 1 | 99.999% uptime at all times of day |
Acme Co patch and upgrade process
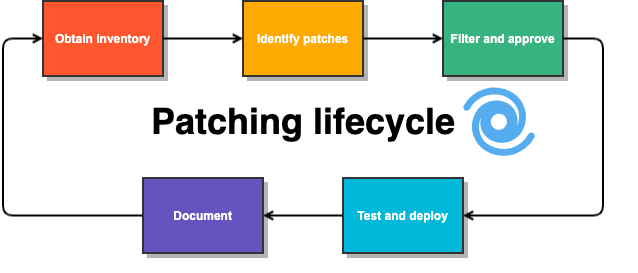
A traditional patch process proposes a systematic approach in which you monitor, patch, and restart an inventory of hosts. In this scenario, you apply the steps of this workflow per host, and the Test and deploy state is time-consuming. This is burdensome for regular maintenance on a rapid cadence of updates, and there are many cycles of repeated patch management.
Manual updates
You can update these servers via traditional hand patching. Traditional hand patching is where someone logs into each of the systems, wrestles with packages despite there being a package manager, and then hopes that the system comes back online on the new kernel after the final reboot. This is not a very good method. It costs a lot of time and people power.
You can automate your patching. This does save on costs, but as your systems age, the potential for configuration drift increases. You're no longer sure that what you have running is what you initially deployed.
A possible enterprise patch and upgrade process
A standard approach is well known and documented in the IT world, but this general approach doesn’t consider more powerful high-availability (HA) technologies.
Syntho Corp ephemeral deployment and redeployment process
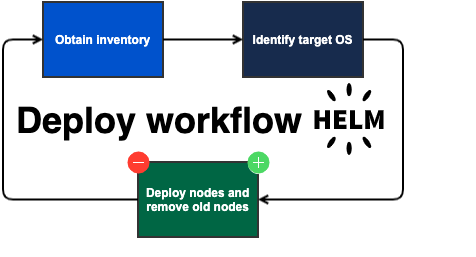
Since the goal of patch management is compliance, we can find other valid ways to meet compliance without a standard patch cycle. Specifically, we can focus instead on improving our deployment and redeployment process. Combined with Atlassian Data Center products' high-availability options, we can reduce or entirely remove downtime imposed on patching. The solution is to add new nodes built on patched operating systems and then simply remove the out-of-compliance nodes. This saves time and effort in the long run.
A possible method to accomplish OS compliance without full-patching of existing app hosts
We can achieve app server OS patching without downtime by leveraging the Atlassian Data Center high-availability features, such as clustering and adding or removing nodes.
Keeping the app running while patching the OS
Zero-downtime application upgrades
This document is mostly concerned with infrastructure patching and upgrades. You may have your app nodes running on hosts or Virtual Machines that can take advantage of this process.
If you’d like to know more about how you can upgrade Jira or other tools without downtime, check out Zero Downtime Upgrades for Jira, Confluence, and Bitbucket
Block level file system snapshots Your shared home directory must be on a file system volume capable of atomic (block level) snapshots, for example, Amazon EBS, LVM, NetApp, XFS, or ZFS. These technologies are becoming increasingly common in modern operating systems and storage solutions. Suppose your shared home directory volume pre-dates these technologies (before using zero downtime backup). In that case, you must first move your shared home directory onto one that supports block-level snapshots. You also need to script the steps to snapshot the volume in the backup process. The atlassian-bitbucket-diy-backup script does not include fully worked examples for every vendor technology. Please consider another backup strategy if you can't create such a snapshot. Database snapshot technology Your database must be capable of restoring a snapshot close to the same point in time as the home directory snapshot. The easiest way to do this is to take database snapshots close to the home directory backup time. Alternatively, some databases support a vendor-specific "point-in-time recovery" feature at restore time. All database vendors supported by Bitbucket provide tools for taking fast snapshots and point-in-time recovery. This article can provide more information. Ensure you have enough capacity to run the cluster, then shut down a running node on which to perform the operation.
Copy the entire home and installation folder to a new host/node.
Start the first node and wait for it to start up.
Start the new node and wait for it to start up.
Instead, you can approach this by adding new nodes and removing old ones until you’ve completely shut down all old nodes.
Shut down a running node.
Copy the entire home and installation folder to a new host/node with a patched OS.
Start the new node and wait for it to start up.
Copy the home and installation folder to additional nodes as needed (one at a time) and remove existing nodes.
Resources