Monolithic Bitbucket deployment guidance
Objective
This article will provide guidance for large-scale, monolithic deployments of Bitbucket. It will detail architectural guidelines for primary clusters and describe the purpose and usage of mirror farms for large deployments.
Please note: This guidance will change when Bitbucket 8.x LTS is released with BB Mesh (Data Center roadmap)
High-level architectural summary
Smart mirrors are the key to properly scaling Bitbucket deployments. At a high level, there are two main deployments necessary:
- (UI) Main deployment aka primary cluster
- (CI) [Multiple] mirror farms with dedicated hardware, geographically located near hotspots
Primary cluster
- Intended for human traffic only
- Minimize CI load as much as possible on this environment (see “Traffic shaping and smart mirrors” section below)
- Put monitoring in place to track offending CI, move to mirror farm
Smart mirrors or mirror farms
- Set of nodes separate from the primary cluster
- Separate DB from primary cluster
- Use the local, internal database, not an external shared database
- Dedicated storage
- Local disk is required, not NFS, and you cannot use shared storage across mirror nodes
- Low latency to main UI deployment
- Mirror farm in each geo for CI (if necessary)
Considerations for scaling the primary cluster properly
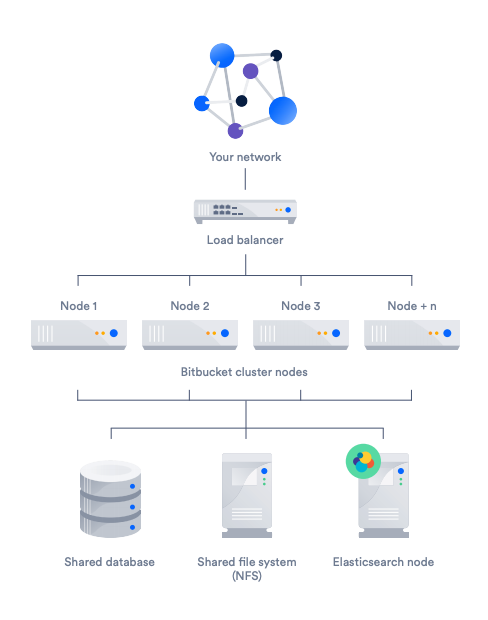
- Make sure the primary cluster is at the right scale.
- A standard Bitbucket Data Center cluster implementation is comprised of a number of machines, each with its own purpose.
- A load balancer distributes the request across the nodes.
- A single Bitbucket Data Center cluster can have up to 8 nodes. Atlassian has tested up to 12, but exceeding 8 nodes is not recommended due to performance degradation.
- An Elasticsearch node enables searching for projects, repositories, and code.
- The network backbone between nodes on the cluster should be at least 1 Gbps, with user-facing NICs of 10 Gbps.
- A shared database and file system (NFS) enables equal access to the data from each node.
- The network backbone from nodes to NFS should be the fastest, lowest latency connection possible.
- Additional details about resource scaling can be found at Scaling Bitbucket Server | Bitbucket Data Center and Server 7.6.
- If users are hitting the "Bitbucket Server is reaching resource limits..." banner, some additional details can be found here: Bitbucket Server is reaching resource limits | Bitbucket Data Center and Server KB.
- To get information about the size and traffic of an environment, the Bitbucket load profile documentation will walk you through how to get useful numbers on repositories, users, pull requests, and traffic.
Leveraging smart mirrors
In general, if most of the load is automated hosting load, it's better to scale up the size of the mirror farm, rather than the size of the primary cluster, since mirror farms can be used to scale far beyond the 8 node limit of a primary cluster. For customers with development teams in multiple geographical locations, the use of smart mirroring can greatly improve large repository Git clone speeds.
How smart mirrors work
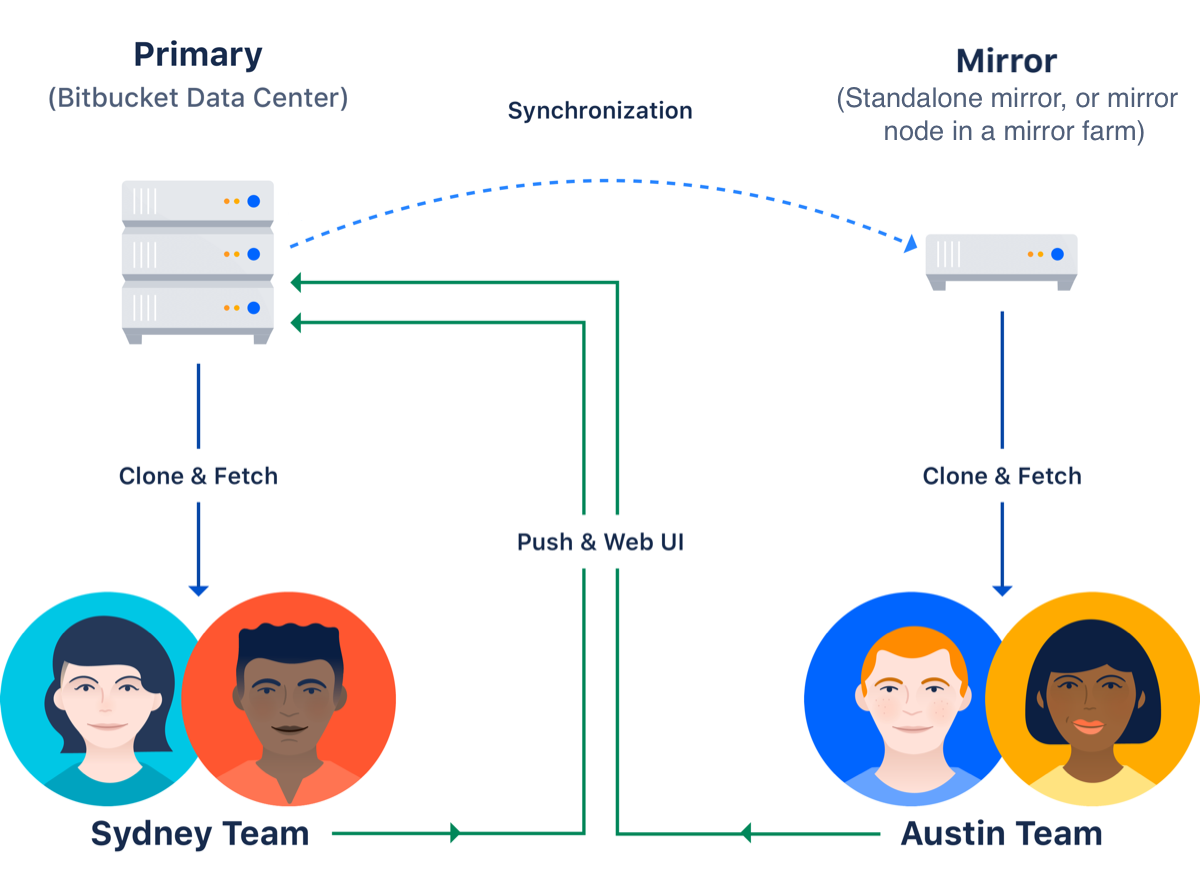
Treating the primary Bitbucket Data Center instance as the source of truth:
- Smart mirrors host read-only copies of repositories in remote locations to eliminate excessive wait times for clone/fetch activity. Admins can decide whether or not to host all or a subset of the primary’s Git repositories per mirror. Each mirror includes an anti-entropy system that verifies the consistency of the mirror against the primary every 3 minutes.
- User credentials are delegated back to the primary server through the mirror to eliminate the need for duplicated user management.
- Commits/pushes are funneled directly back to the primary instance. The primary then takes care of redistributing the changes to the appropriate mirrors.
Types of smart mirror configurations
Depending on the number/size of development teams, the size of the primary Bitbucket instance, and the amount of data to be designated to each location, there are two options to choose from:
- A single mirror in each geolocation is suitable for the following:
- Small development teams (5-10 members) per location
- A limited subset of projects/repositories to replicate
- Load is not consistent (i.e. only at quarter or year-end) and therefore does not warrant multiple mirrors
- For more information about setting up a single mirror, please refer to Set up a mirror | Bitbucket Data Center and Server 8.4
- A mirror farm with multiple mirror nodes in each geolocation is suitable for the following:
- Multiple or large development teams per location
- Replication of the entire primary instance is required at each individual geolocation
- For more information on how to set up a mirror farm, please refer to Set up and configure a mirror farm | Bitbucket Data Center and Server 8.4
Hardware considerations for mirrors
- Always use the internal database for mirrors. The amount of data stored in the database on a mirror is minimal.
- Do not use an NFS for the mirror storage. While it may still operate, it will slow down the UI interactions. Use the local filesystem on the mirrors or a storage area network (SAN).
- Use a minimum of two mirror cluster nodes.
- Is there an upper bound for mirrors?
- Hazelcast usage on mirrors is much smaller than on a full cluster, so mirror farms can scale out higher than the primary cluster.
- Internally, we’ve tested 16 nodes. At the time mirror farms were built that was considered “a lot of hosting capability”.
- Mirror farms might have a few rough edges, so customers might hit other limitations. For example, huge numbers of repositories might result in slow syncing.
- For mirrors to upstream, there aren't any real latency requirements. For mirrors in a farm, latency between the mirrors should be low because they communicate over Hazelcast to coordinate updates.
- It is possible to deploy multiple mirror farms. Four mirror farms with 16 nodes each is a viable deployment strategy.
- It's extremely difficult to provide numbers for CPU/memory, aside from simply saying, "More is always better." Repositories have many different dimensions they can be "big" in (big history, big trees, big blobs, big refs, etc.) and all of them have an impact on hosting performance. However, here are some rough guidelines for choosing hardware:
- Estimate the number of concurrent clones that are expected to happen regularly (look at continuous integration). Add one CPU for every two concurrent clone operations.
- Estimate or calculate the average repository size and allocate 1.5 x number of concurrent clone operations x min (repository size, 700MB) of memory.
- If running Bitbucket Data Center, check the size using the Bitbucket Data Center load profiles. If the instance is Large or XLarge, take a look at the infrastructure recommendations for Bitbucket Data Center AWS deployments.
Data replication considerations
When setting up either a single mirror or a mirror farm with multiple nodes, you must decide how much of the primary instance’s data will be replicated. As mentioned above, the two main options are:
- All projects of the primary instance
- In the case of dependency complexity or cross-team collaboration, it may be necessary to replicate everything to each mirror.
- Note: If all projects are initially chosen for replication, it is not possible to remove individual projects as needed. The mirror will have to be completely removed and reinstalled in order to target individual projects.
- Individual projects or a subset of projects
- An example of this would be sensitive/proprietary codebases with limited access, geographic restrictions, or those with few, very clearly defined dependencies.
- Projects can be added or removed as needs change.
Communication is key
The Bitbucket admin and the project admin must work together if individual projects or subsets of projects are being replicated. Only a Bitbucket admin can configure the projects to mirror. However, in most cases, the project admin is necessary to make sure the correct list of projects to mirror is chosen as the build process might have dependencies on repositories across projects.
Project admins should keep two things in mind:
- Once a project is being mirrored, any new repositories that are added to that project are automatically replicated.
- If you're moving from mirroring all projects to a subset of projects, the mirror will have to be completely removed and reinstalled.
Build tool considerations
Currently, when Bamboo connects to the primary Bitbucket instance, it uses the base URL to perform any Git operations. To make the URL available for mirrored instances, use the generic Git for mirrored repositories. This consideration would hold true for any build tool the developers are using.
Traffic shaping and smart mirrors
The automation of traffic shaping for smart mirrors is not possible. As mentioned above in the "Build tool considerations" section, mirrors don't use the same URL structure as the primary Bitbucket instance (this will change when mirror maintainability is released). Procedurally, organizations can provide guidance to their developer communities in an effort to route traffic appropriately:
- All non-human initiated traffic should target a mirror, including all build tools.
- For human-initiated traffic, Git commands in the same geolocation should use primary, otherwise the mirror should be targeted instead.
- REST APIs are not serviced by mirrors. All REST requests must be directed to the primary cluster.
Additional mirror resources
- Support geo-distributed teams with Data Center — Free on-demand webinar sign-up
Other considerations
The items in this section are optional, based on your deployment strategies.
Large binary storage options
Regardless of tooling, Git’s intended use is for versioning source files only. While Git LFS was created to help facilitate handling large files, storing large binary files, such as executables, videos, or other media files in Git should be discouraged for the following reasons:
- Binaries, if updated frequently, consume massive amounts of storage compared to source code files, which are text only.
- Even if old binaries are deleted, it is nearly impossible to delete all of the history of the branches or tags associated with the deleted binaries. Meaning, space will never be reclaimed if all of the history is not cleaned up as well.
- If duplicate binaries are stored in multiple projects and subsequent repositories, Without a single source of truth for builds to pull from, there is a greater chance for:
- People using out of date binaries
- Exponential bloat as every repo clones the same large binary over and over again
- Build processing times to be adversely affected waiting for clones to complete
- Build failure due to clones exceeding available storage
Read our recommendations for reducing repository size. While this document is specifically labeled for Cloud, it is an excellent resource in providing the following alternative options for storing binaries/executables in Bitbucket:
- Artifact repositories: Build processes are configured to pull and upload build artifacts to artifact repositories so they can be shared as well as versioned. The more popular of the artifact repository vendors are:
- Docker repository: Instead of storing build executables in Bitbucket, consider building them as Docker images and pushing the images to a Docker repository hosted on Docker Hub, or a local Docker repository.
- AWS S3: For large media files, an S3 bucket can be used as a central location where the files can be easily downloaded. See Using versioning in S3 buckets - Amazon Simple Storage Service for versioning functionality options.
CDN
A content delivery network is useful for static assets to be served by the CDN.
Go to Content Delivery Network in the admin console of the Data Center application. On the Performance tab, check the percentage of requests that had a transfer cost of more than one second. Put simply, the higher the percentage, the more likely it is that the user's requests are being affected by network conditions, such as latency and connection quality.
Scaling in AWS with Ceph
If Bitbucket is deployed in AWS, consider using Ceph storage. While Ceph storage won’t be faster if used with a single node, it can help process large numbers of requests coming in from CI from multiple nodes much faster. Check out this documentation for spinning up Ceph.
Additional Resources
Was this content helpful?
Connect, share, or get additional help
Atlassian Community