Jira Server to Cloud API integration
Overview
This document is a technical guide to help you discover who integrates with your on-prem Jira instance via the API, what is fundamentally different when integrating with a Cloud instance via the API, and how to determine if that integration is compatible with Cloud.
Discovery
One of the first things you'll need to accomplish is finding out who is integrating with your existing Jira instance. While you likely have a general idea of who is pulling and manipulating data in Jira, there are probably some integrations that you aren’t aware of. As part of your due diligence, you should attempt to notify all integration owners about the upcoming changes and potential impacts.
To take an inventory of these integrations, we can do a couple of things:
- Modify Jira logging to capture API traffic and analyze it in the log analyzer tool: Jira Access Log Analyzer
- If you are on Jira 8.14+, review the personal access token admin panel: Using Personal Access Tokens
Review of the personal access token admin panel in Jira 8.14+ will assist with identifying active tokens and authors. It does not provide details about how those tokens are being used.
Analyzing traffic
To add HTTP traffic to the access logs, navigate to System → Logging and profiling and enable HTTP access logs. This will be written to a new file,
<JIRA_INSTALL>/logs/acess_log.YYYY-MM-DD. After an appropriate amount of capture time has passed, import this file into a piece of log analyzing software and separate the data into internal and external API calls.Internal API calls will look like this:
1127.0.0.1 817x210x2 - [10/Aug/2021:13:37:14 -0700] "GET /j8134/rest/gadgets/1.0/g/messagebundle/und/gadget.common%2Cgadget.issuetable%2Cgadget.assignedtome%2Cgadget.issuetable.common HTTP/1.1" 200 2809 5 "-" "Apache-HttpClient/4.5.13 (Java/1.8.0_282)" "-"2127.0.0.1 817x211x2 - [10/Aug/2021:13:37:14 -0700] "GET /j8134/rest/gadgets/1.0/g/messagebundle/en_US/gadget.common%2Cgadget.issuetable%2Cgadget.assignedtome%2Cgadget.issuetable.common HTTP/1.1" 200 2791 5 "-" "Apache-HttpClient/4.5.13 (Java/1.8.0_282)" "-"3127.0.0.1 817x212x2 - [10/Aug/2021:13:37:14 -0700] "GET /j8134/rest/gadgets/1.0/g/messagebundle/und/gadget.common%2Cgadget.activity.stream HTTP/1.1" 200 4018 5 "-" "Apache-HttpClient/4.5.13 (Java/1.8.0_282)" "-"External API calls will look like this:
10:0:0:0:0:0:0:1 818x229x1 admin [10/Aug/2021:13:38:39 -0700] "GET /j8134/rest/api/2/permissions HTTP/1.1" 200 1954 36 "-" "PostmanRuntime/7.26.10" "1blxh0z"With this information, you should be able to identify which user is hitting a specific API endpoint, and how often.
Getting started
For users who are unfamiliar with Cloud APIs, there are a couple of things that are fundamentally different. Additionally, there are a few tips worth pointing out right at the start to accelerate the learning curve.
Authentication
One of the primary differences users and admins will notice when integrating with Jira Cloud over Jira Data Center is the use of API tokens during basic authentication. Users will need an API token that is associated with their Atlassian account to retrieve and/or modify data in Jira. Check out this page for how to get an API token. In practice, users will use the API token as their password when making REST calls.
Expansion
The Jira REST API uses resource expansion, which means that some parts of a resource are not returned unless specified in the request. This simplifies responses and minimizes network traffic.
To expand part of a resource in a request, use the expand query parameter and specify the object(s) to be expanded. If you need to expand nested objects, use the
. dot notation. If you need to expand multiple objects, use a comma-separated list.For example, the following request expands the
names and renderedFields properties for the JRACLOUD-34423 issue:GET issue/JRACLOUD-34423?expand=names,renderedFieldsTo discover which object can be expanded, refer to the
expand property in the object. In the JSON example below, the resource declares widgets as expandable.1{2 "expand": "widgets", 3 "self": "https://your-domain.atlassian.net/rest/api/3/resource/KEY-1", 4 "widgets": {5 "widgets": [],6 "size": 57 }8}Pagination
The Jira REST API uses pagination to improve performance. Pagination is enforced for operations that could return a large collection of items. When you make a request to a paginated resource, the response wraps the returned array of values in a JSON object with paging metadata. For example:
1{2 "startAt" : 0,3 "maxResults" : 10,4 "total": 200,5 "isLast": false,6 "values": [7 { /* result 0 */ },8 { /* result 1 */ },9 { /* result 2 */ }10 ]11}startAtis the index of the first item returned in the page.maxResultsis the maximum number of items that a page can return.- Each operation can have a different limit for the number of items returned, and these limits may change without notice.
- To find the maximum number of items that an operation could return, set
maxResultsto a large number — for example, over 1000 — and if the returned value ofmaxResultsis less than the requested value, the returned value is the maximum.
totalis the total number of items contained in all pages.- This number may change as the client requests the subsequent pages, therefore the client should always assume that the requested page can be empty.
- This property is not returned for all operations.
isLastindicates whether the page returned is the last one.- This property is not returned for all operations.
Ordering
Some operations support ordering the elements of a response by a field. Check the documentation for the operation to confirm whether ordering a response is supported and which fields can be used. Responses are listed in ascending order by default. You can change the order using the
orderby query parameter with a - or + symbol. For example:?orderBy=nameto order bynamefield ascending.?orderBy=+nameto order bynamefield ascending.?orderBy=-nameto order bynamefield descending.
Server vs. Cloud endpoints
Most API endpoints that exist in Server/Data Center exist in Cloud and vice versa. For any user that integrates with Jira Server/Data Center via the API, we recommend they ask themselves these questions:
- What data do I need from Jira to accomplish my task?
- What REST endpoint am I hitting?
- Does that REST endpoint exist in Cloud?
- If the endpoint does not exist, is there another endpoint that returns the data I need?
Furthermore, we recommend that every API integration be evaluated to determine not just it’s usefulness, but also:
- How often is it running vs. how often should it be running?
- Is there a cheaper way to return the same data?
- e.g. requesting all issues in every project to see what is overdue vs. requesting all issues in just the relevant project
Based on the answer to these questions, admins should be able to reduce the overall load on the system.
Reading the API documentation
If you are not familiar with Atlassian’s API documentation, it can be a bit confusing if you don’t know your way around. Let’s break down the general structure of what is on the page.
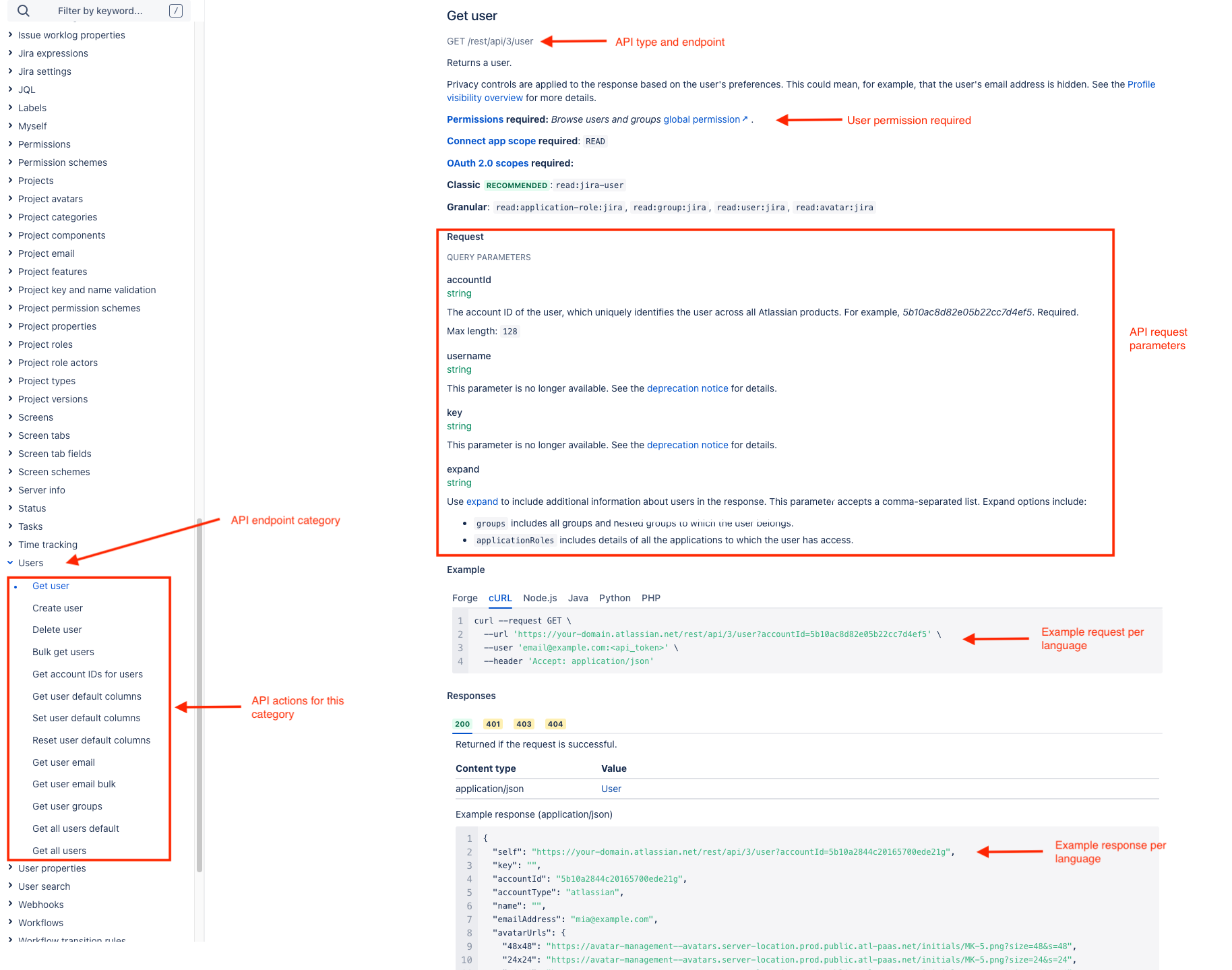
This structure is the same for each API category and each action for that category.
APIs for admins
If you're an admin for the organization at large, there are a slew of additional APIs available to you. Check out:
- Org-level user management APIs: For modifying profiles and/or revoking API tokens (which is paginated by individual users)
Additional resources
Videos
Was this content helpful?
Connect, share, or get additional help
Atlassian Community